
风能否向月而行。
效果展示
【AI-胡桃】 翻唱 - 丫头
【AI-芙宁娜】 翻唱 - 轻涟(中文)
【AI-芙宁娜】 翻唱 - ありがとう(泪的告白)
【AI-芙宁娜】 翻唱 - 堕
相关教程和参考资料
so-vits-svc 项目地址: https://github.com/svc-develop-team/so-vits-svc.git
官方 README 文档:https://github.com/svc-develop-team/so-vits-svc/blob/4.1-Stable/README_zh_CN.md
B 站 up Sucial的非常详细的教学视频: https://www.bilibili.com/video/BV1Hr4y197Cy?p=1&vd_source=98a6ce1d2586467c3641a8b5aac049ed
教学视频的笔记: https://github.com/SUC-DriverOld/so-vits-svc-Chinese-Detaild-Documents?tab=readme-ov-file
B 站 up Sucial的UVR5人声分离教程: https://www.bilibili.com/video/BV1F4421c7qU/?vd_source=98a6ce1d2586467c3641a8b5aac049ed
一些报错的解决办法(来自 B 站 up:羽毛布団): https://www.bilibili.com/read/cv22206231/
关于环境配置
需要 显存 6G+,并设置虚拟内存 20G+;
需要 NVIDIA-CUDA,版本11.7,11.8或版本12,请安装。
查看cuda 版本
nvcc -V
需要 安装 visual studio 2022,组件里装”使用 c++的桌面开发”。否则依赖包 fairseq 会安装失败。
需要环境管理系统 conda,请安装。
源码下载4.1-Stable稳定版 https://github.com/svc-develop-team/so-vits-svc.git
vsCode 打开项目,在控制台使用 conda 创建虚拟环境,并启用
//创建名称为 env_so_vits_svc 的虚拟环境并安装python 3.9版本。
conda create -n env_so_vits_svc python=3.9
//查看是否创建成功
conda env list
//启用环境
conda activate env_so_vits_svc
修改 requirements_win.txt 文件, 将 gradio>=3.7.0 改为 gradio==3.41.2, 将 scipy==1.7.3 改为 scipy==1.13.0,(解决与numpy的版本不匹配警告问题) 并添加三个依赖包 fastapi==0.84.0 pydantic==1.10.12 tensorflow
gradio==3.41.2
scipy==1.13.0
fastapi==0.84.0
pydantic==1.10.12
//用于辅助判断训练结果
tensorflow
然后安装依赖包 (windows)
pip install -r requirements_win.txt
安装Pytorch, 版本要与CUDA对应,Pytorch 官网https://pytorch.org/get-started/locally/
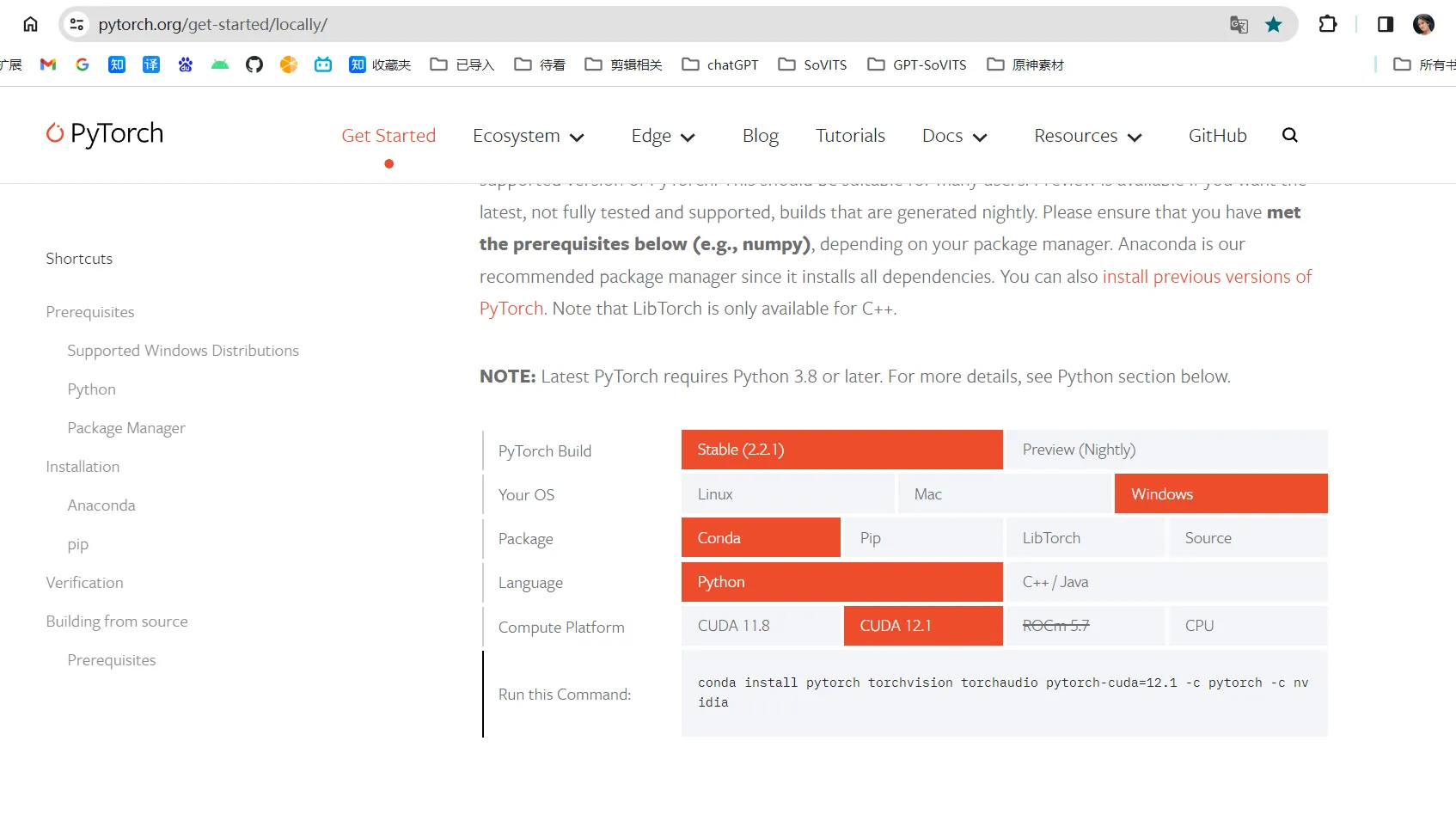
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
验证是否安装成功
python
# 回车运行
import torch
# 回车运行
print(torch.__version__)
# 回车运行
print(torch.cuda.is_available())
# 回车运行
//最后一行出现True则成功,出现False则失败,需要重新安装.
音频数据集准备
-
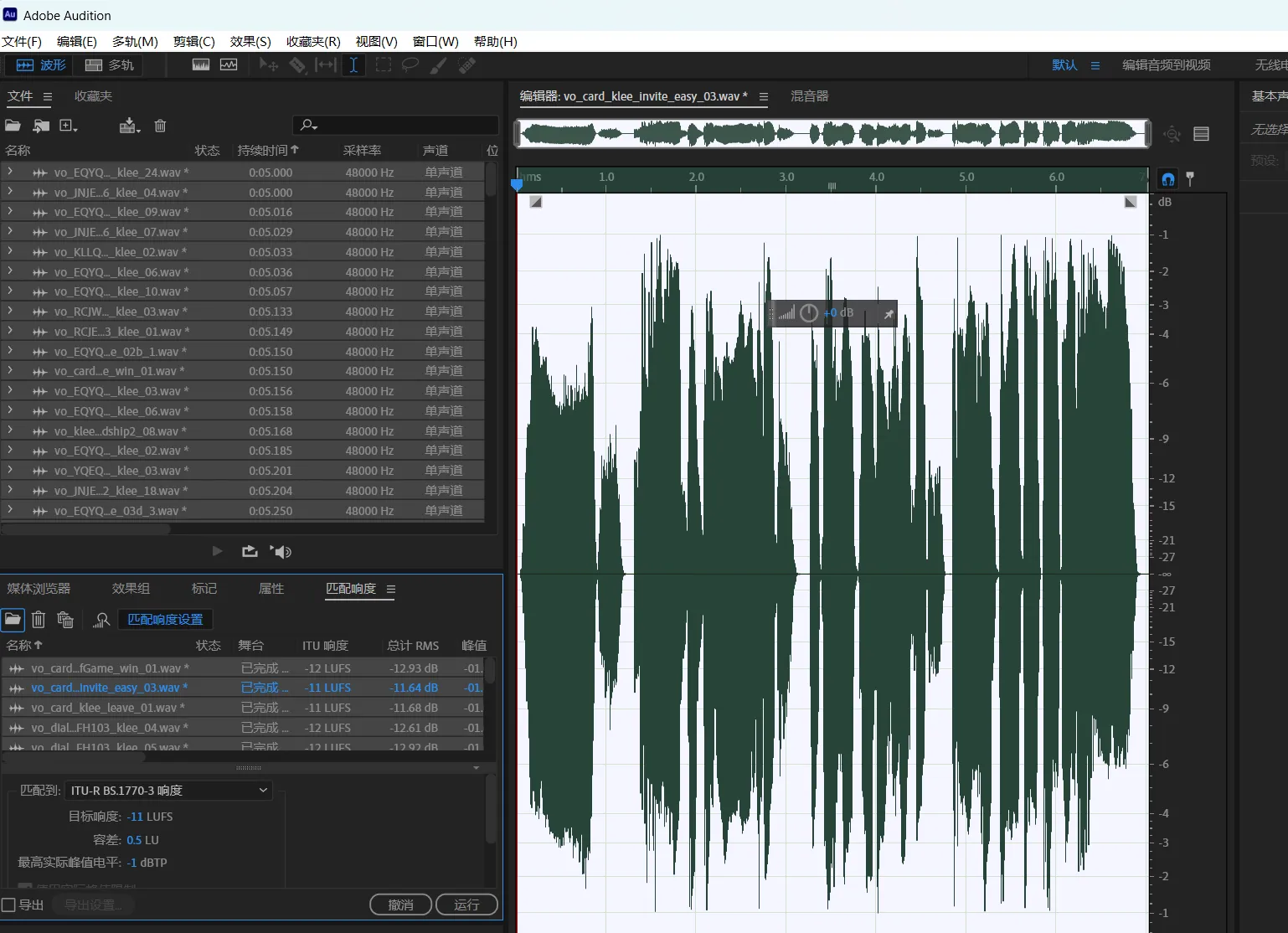
音频格式为wav,通过 Adobe Audition 的持续时间排序功能,删除时长 比较短的和比较长的,(回到原文件夹再次删除所有音频,由于Adobe Audition程序占用着没有删除的音频,从而无法删除占用音频,但是能够删除在Adobe Audition 中删除的音频,以此达到我们的过滤删除目的)每条时长在5s~15s之间最佳,过长容易爆内存,保留150条数据以上,然后拖拽所有文件到下方,选中所有,匹配响度。关闭Adobe Audition,保存所有。 (注:可以通过windows资源管理器直接删除不符合要求的音频,选择 排序-》分组依据-》大小,即可对音频重新排序,比AU简单方便。)
-
回到原文件夹,删除因为匹配响度而产生的所有.pkf文件.
- 将数据集放入项目中的 dataset_raw 目录,数据集以人名命名即可,不可为中文,原则上可同时训练多个人的声音模型,我同时训练了3个,出现了节奏不对的问题,不知道是否是因为同时训练产生的。建议单独训练,且训练1个和多个的时间是累加关系,所以同时训练多个并不会节省时间。
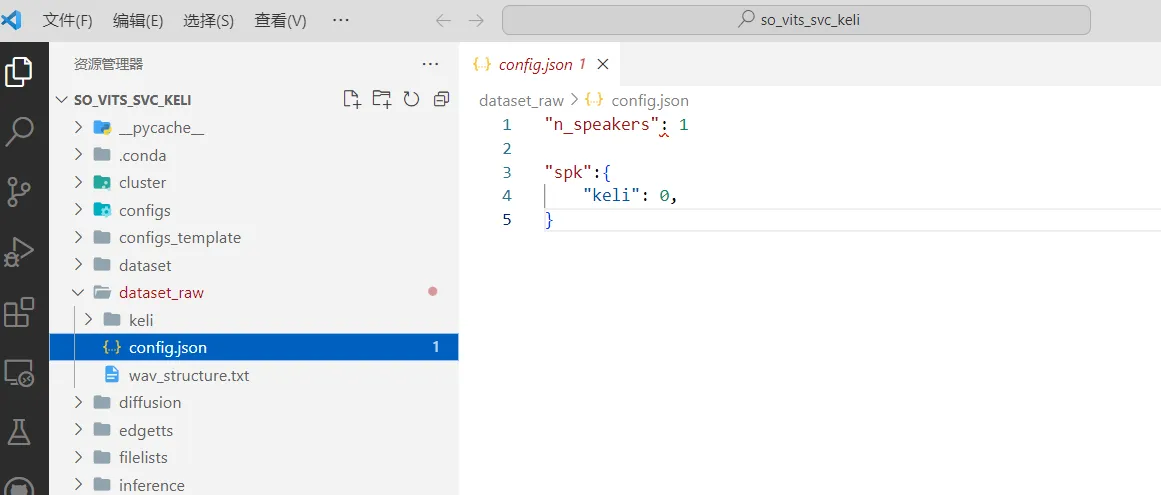
dataset_raw ├───speaker0 │ ├───xxx1-xxx1.wav │ ├───... │ └───Lxx-0xx8.wav └───speaker1 ├───xx2-0xxx2.wav ├───... └───xxx7-xxx007.wav - 在dataset_raw下创建config.json文件。
"n_speakers": 1 "spk":{ "文件夹名字(不可为中文)": 0 }
预先下载的模型文件
-
使用 contentvec 作为声音编码器(默认且推荐) 下载 contentvec :checkpoint_best_legacy_500.pt https://ibm.ent.box.com/s/z1wgl1stco8ffooyatzdwsqn2psd9lrr 放在pretrain目录下.
或者下载下面的 ContentVec,大小只有 199MB,但效果相同:
contentvec :hubert_base.pt https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt , 将文件名改为checkpoint_best_legacy_500.pt后,放在pretrain目录下. -
预训练底模文件: G_0.pth, D_0.pth 放在logs/44k目录下.
扩散模型预训练底模文件: model_0.pt 放在logs/44k/diffusion目录下.
https://huggingface.co/Sucial/so-vits-svc4.1-pretrain_model包含G_0.pth,D_0.pth,model_0.pt.s
预训练的 NSF-HIFIGAN 声码器 :nsf_hifigan_20221211.zip https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
解压后,将四个文件放在pretrain/nsf_hifigan目录下
程序执行
-
重采样至 44100Hz 单声道,添加–skip_loudnorm 跳过响度匹配步骤.
python resample.py --skip_loudnorm执行成功后,.\dataset\44k 目录下将生成音频文件,如下图
- 自动划分训练集、验证集,以及自动生成配置文件,增加–vol_aug 参数使用响度嵌入。
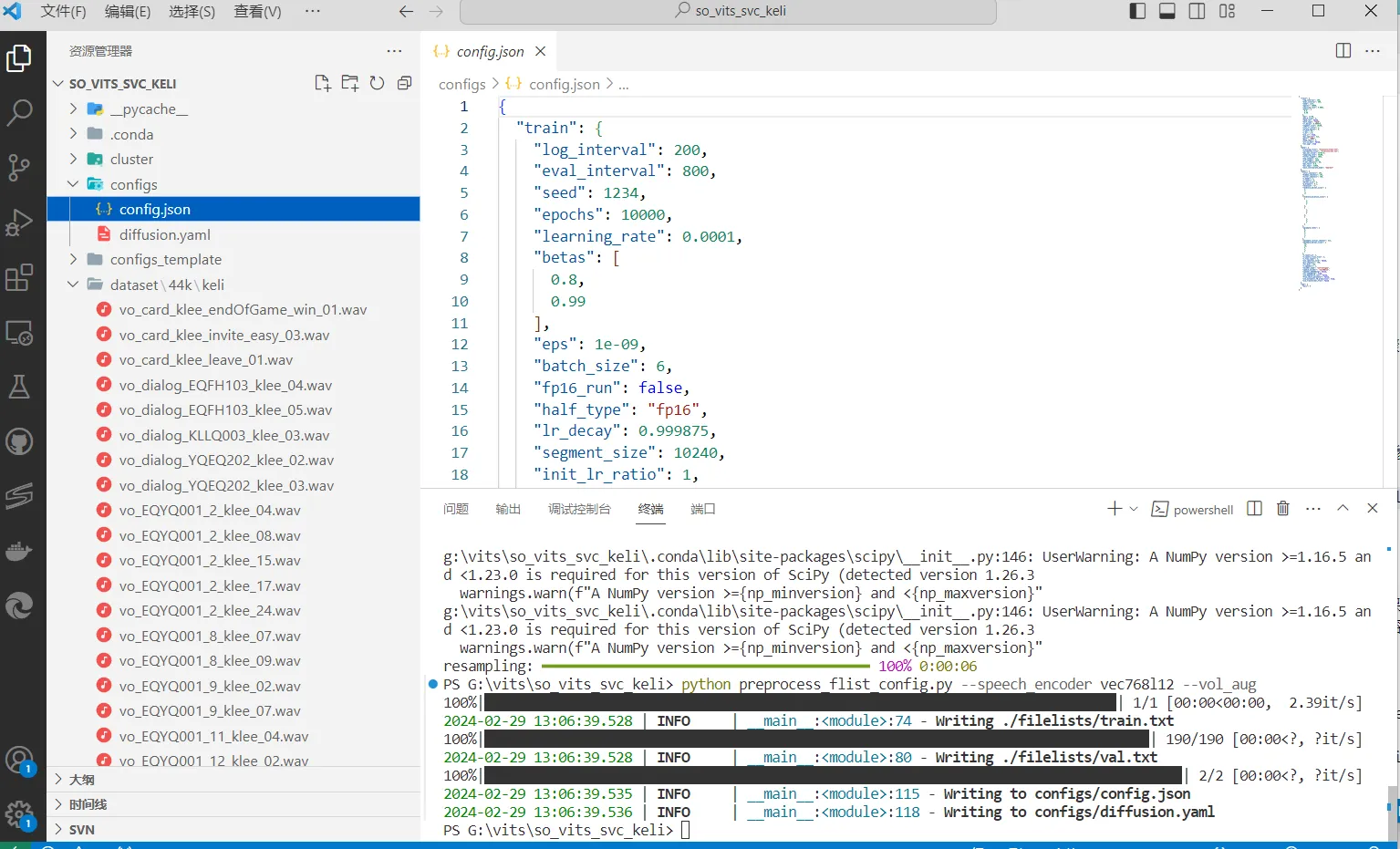
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug运行完毕后 .\configs\ 目录下将生成 config.json 与 diffusion.yaml 文件
此时可以在生成的 config.json 与 diffusion.yaml 修改部分参数
keep_ckpts:训练时保留最后几个模型,0为保留所有,默认只保留最后3个。
batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可,默认是6,6g显存的需调为3比较好。如下图
-
生成 hubert 与 f0。尚若需要浅扩散功能(可选),需要增加–use_diff 参数.执行需要一定时间。
python preprocess_hubert_f0.py --f0_predictor dio --use_diff执行成功后,每个音频文件都生成了5个相关的文件,如下图
-
主模型训练,需要epoch 5000+,追求效果建议epoch > 9000,训练时间与训练集大小和显卡性能相关,3小时数据集 + 4070Ti 12G显卡+ epoch=10000,大约需要120小时。训练过程中 可ctrl+c中断,继续训练再次执行训练命令即可。
python train.py -c configs/config.json -m 44k扩散模型训练(可选),测试效果:我没听出来有啥变化。
python train_diff.py -c configs/diffusion.yaml模型训练结束后,模型文件保存在logs/44k目录下,扩散模型在logs/44k/diffusion下。
-
模型压缩/打包分享
生成的模型含有继续训练所需的信息。如果确认不再训练,可以移除模型中此部分信息,得到约 1/3 大小的最终模型。
生成模型大小在600M~800M,压缩后200M左右。python compress_model.py -c="configs/config.json" -i="logs/44k/G_30400.pth" -o="logs/44k/release.pth" - 训练结果的判断
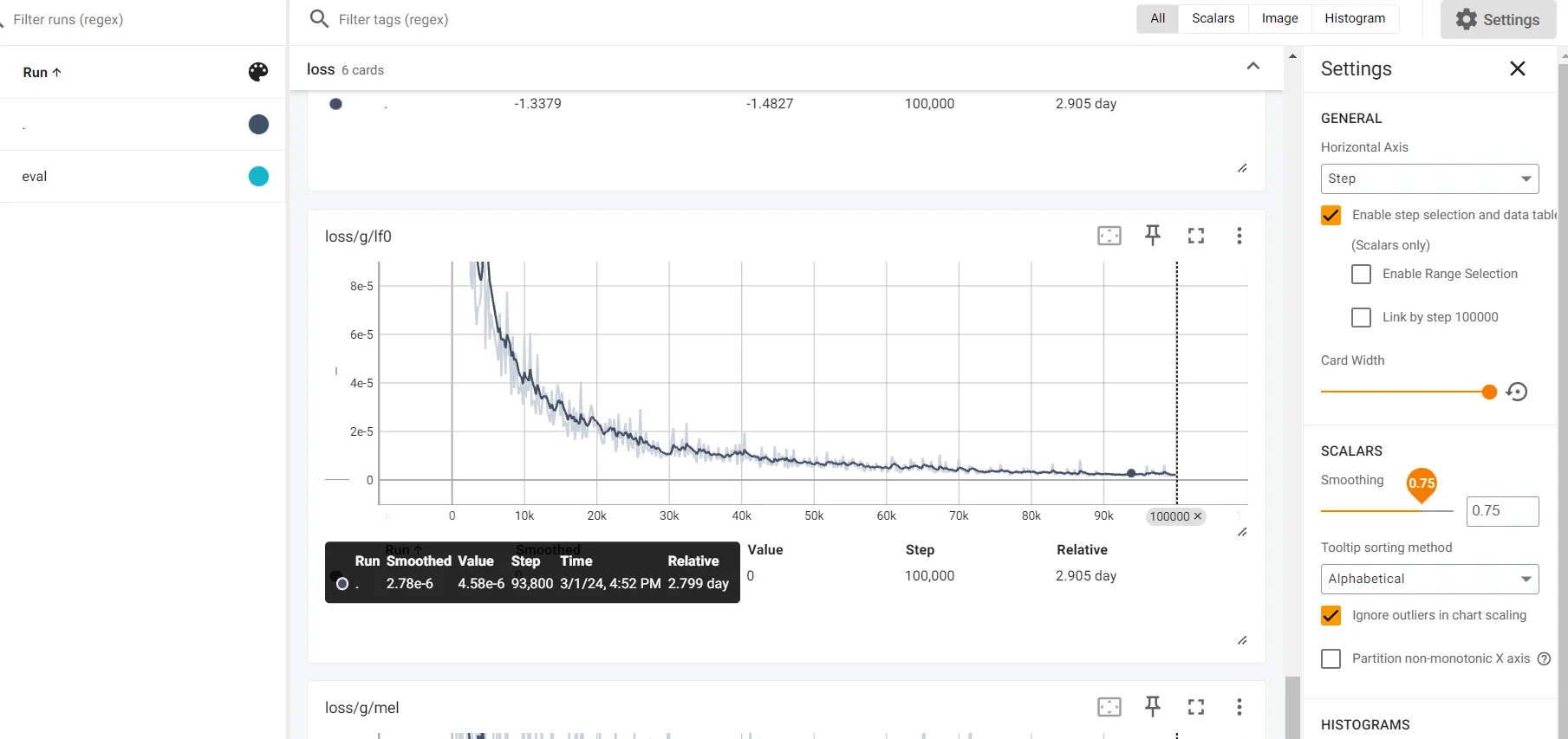
// 启动 tensorboard ,命令行输入 python -m tensorboard.main --logdir=logs\44k命令行返回一个本地地址,浏览器打开地址,需要等待训练200步之后才会出现表格。此时命令行窗口不能关闭。 如何判断训练的差不多了?找到 loss 标签下的 loss/g/lf0,当图像趋于稳定的直线时,则说明训练的差不多了,此时去推理听一听结果在做判断。下图是训练十万步的结果。
由于命令行开启 tensorboard 会占用命令行窗口,写一个 .bat 执行文件,专门用于打开tensorboard,命名为 启动tensorboard.bat 即可,放在项目根目录下,双击点开即可
chcp 65001
@echo off
echo 正在启动Tensorboard...
echo 如果看到输出了一条网址(大概率是localhost:6006)就可以访问该网址进入Tensorboard了
//D:\Anaconda\envs\env_so_vits_svc 替换这个地址为自己的conda环境地址
D:\Anaconda\envs\env_so_vits_svc\python.exe -m tensorboard.main --logdir=logs\44k
pause
目标音频处理 uvr5工具
推理
- 使用以下命令打开 webui 界面,推理期间,此命令行窗口不能关闭。
python webUI.py由于命令行开启 webui 界面会占用命令行窗口,写一个 .bat 执行文件,专门用于打开推理界面,命名为 启动 webui.bat 即可,放在项目根目录下,双击点开即可
chcp 65001 @echo off echo 初始化并启动WebUI……初次启动可能会花上较长时间 echo WebUI运行过程中请勿关闭此窗口! //D:\Anaconda\envs\env_so_vits_svc 替换这个地址为自己的conda环境地址 D:\Anaconda\envs\env_so_vits_svc\python.exe webUI.py pause
- 模型选择 .\logs\44k\G_步数.pth 文件,配置文件选择 .\configs\config.json
下面的音频选择 选择处理好的干声。
其他参数不需要动。 - 点击音频转换,生成推理后的音频。
- 通过其他软件比如 剪映 合成 推理后的音频 + 伴奏,完成。
关于文字转音频,点击文字转音频,输入文本,勾选上方F0预测,点击转换即可。
关于 conda
Conda是一个开源的软件包管理系统和环境管理系统,用于安装和管理软件包及其依赖项。它最初是为Python语言设计的,但也可用于其他语言和工具。Conda允许用户轻松地创建、分享、管理和部署环境和软件包,使开发人员能够更有效地管理项目的依赖关系。
Conda的主要特点包括:
- 软件包管理:Conda可以安装、更新、卸载和管理软件包及其依赖项。
- 环境管理:Conda允许用户创建多个隔离的环境,每个环境都可以拥有不同版本的软件包,从而使得不同项目之间的依赖关系可以互相隔离,避免冲突。
- 跨平台性:Conda支持在不同的操作系统上运行,包括Windows、macOS和Linux。
- 开源和社区支持:Conda是开源的,有一个活跃的社区支持,用户可以分享和贡献软件包和环境。
总的来说,Conda是一个强大而灵活的工具,可以帮助开发人员更轻松地管理项目的依赖关系,提高开发效率。
//conda 的版本查看
conda -V
//存在的conda环境查看,正在启用的环境会有*标。
conda info --envs
或者
conda envs list
//创建 名为 pytorch_gpu, python版本为3.9 的虚拟环境
conda create -n pytorch_gpu python=3.9
//启用名为 pytorch_gpu 的环境,
conda activate pytorch_gpu
//取消正在启用环境
conda deactivate
//删除创建的环境
conda env remove --name <环境名称>
关于 问题、建议
- 音频数据集理论上越多越好,越多也就意味着训练模型时的时间成本越高。
- 音频数据集质量(清晰度、有无杂音)很重要,直接影响结果。
- 音频数据集的音调范围,数据集中有高音、低音的样本,在推理后才会有相应的结果,比如数据集中没有高音的样本,推理了一首高音的歌曲,会出现哑音、唱不上去的现象。
- 音频数据集的数据后缀需要小写的 .wav,大写的(.WAV)项目不支持,要注意。
- 尽量找和模型音色相近的音乐干声。相近的和差距很大的音色最后合成的效果差距很大。
- epoch 5000+以上,测试想要一个不错的结果训练时常需要100个小时以上。epoch次数在log里查看。
- 我尝试了一次训练了3个模型,结果推理后的歌曲有两个模型有节拍不同步的问题,不知道具体原因是什么,建议一次只训练一个模型。
- 训练过程中关闭不用的程序等减少内存占用,其他程序的cpu、gpu的使用,会导致训练epoch的时间增长。推理的使用和tensorboard的使用也会这样,不用时及时关闭,保证电脑资源尽量多的给到训练程序。
- 需要训练的声音要有足够的自己的声音特色。